RocketMQ设计原理
本文共 1817 字,大约阅读时间需要 6 分钟。
路由注册,发现,剔除机制
rocketMq topic路由的注册,相当于dubbo来说 (实时模式),采用的是拉取模式
- Broker每30秒向NameServer发送心跳包,心跳包包含主题的路由信息,NameServer会通过HashMap更新
- NameServer以每10s的频率清除已宕机的Broker,NameServer会任务Broker宕机的依据是如果当前系统时间戳件去最后一次收到Broker心跳包的时间戳大于120s
- 消息生产者以每秒30s的频率去拉取主题的路由信息,即生产者并不会立即感知Broker服务器的新增和剔除
使用拉模式的缺点
- Topic是基于最终一致性的,极端情况下会出现数据不一致
- 客户端无法实时感知路由信息变化,例如某一台Broker自身进程未关闭,但停止向NameServer发送心跳包,但生产者无法立即感知该Broker服务器的异常,会对于消息发送造成一定可用性
消息发送高可用设计
消息发送的流程包括
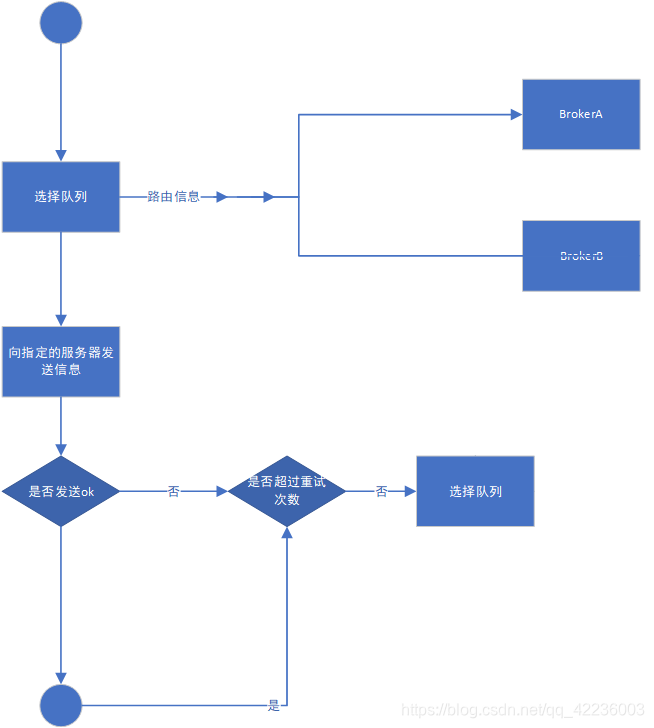
- Topic路由寻址
- 选择消息队列
- 消息发送,重试(默认重试2次),Broker规避 默认使用轮询,实现负载均衡
RocketMQ存储设计
Commitlog
消息存储文件:所有的主题消息随着到达Broker的顺序写入commitlog文件,每一个文件默认为一个G,文件使用该存储信息的第一个全局偏移量来命名文件,这样设计主要是为了方便根据消息偏移量快速定位到所在的物理位置,使用顺序写ConsumeQueue
消息消费队列文件,是Commitlog文件基于Topic的索引文件,主要用于消费者根据Topic消费消息,其组织方式为/topic/queue,同一个队列中存在多种文件,每一个条目使用固定长度(8字节commitlog物理偏移量,4字节消息长度,8字节tag hascode),主要存储hashcode,可以使用访问数组下标的方式快速定位indexFile
基于物理磁盘实现Hash索引,其文件由40字节的文件头,500w的哈希槽,每一个hash槽位4个字节,最后由2000万个index条目,每一个条目由20字节组成,基于文件的hash索引消息消费
消息消费通常考虑消息队列负载,消费模式,消息过滤,消息消费,拉取机制,消息进度反馈,消息消费限流等方面
消息队列负载
集群内的消费者共同承担主题下面的所有消息的消费,即一条消息只能被集群中的一个消费者消费。其队列负载原则是一个消费者可以承担同一个主题下的多个消息消费队列,但是同一个消息消费队列同一时间只允许被分配给一个消费者 消息消费模式 集群消费和广播消费 消息拉取模式 推,拉,本质为拉 消息消费 顺序消息,并发消息,每一个消费者使用独立的线程池来拉取消费端的限流主要包括两个维度
主要为了保护消费者不会因为内存溢出而溢出, 例如调用消息服务没有超时时间可能会导致消息堆积
消息堆积数量
消息超过1000条会触发流控,具体做法是放弃本次拉取,延迟50ms后将该任务放进pullRequestQueue,会打应消费端日志 消息堆积大小 超过10M触发并发拉取和消费的核心
pullMessageService线程和RebalanceService线程的交互 每一个消费组一个线程池,用来异步处理消息 消费进度反馈主从同步
读写分离,不提供主从切换
消费流程
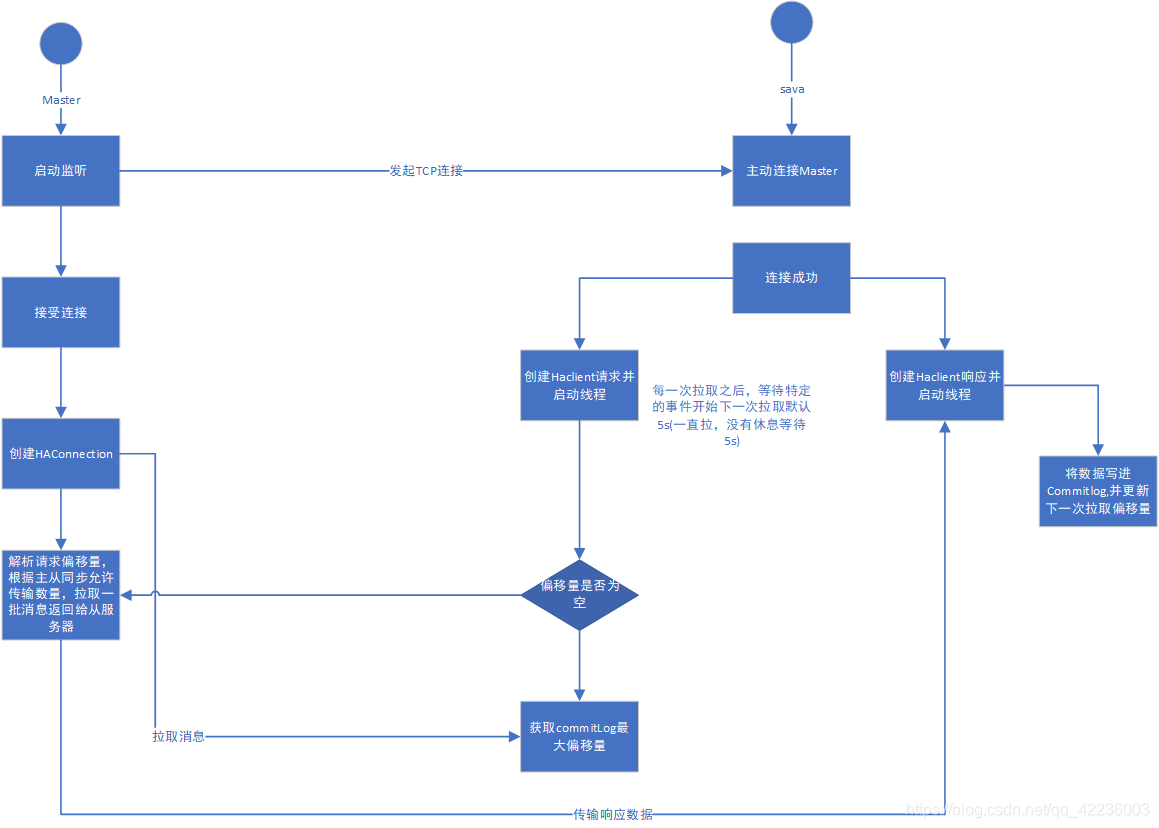
- 首先确定Master在指定端口监听
- 客户端启动,主动连接master,建立TCP连接
- 客户端以每5s向服务端拉取消息,如果是第一次拉取的话,先回去commitlog文件中最大偏移量,以该偏移量向服务端拉取消息
- 服务端解析请求,返回数据
- 客户端收到第一批消息,将消息写入commitlog,然后向master汇报拉取进度,并更新下一次偏移量
- 重复第三步
主从服务器在运行过程中,消费者一般从主服务器拉取,当主服务器积压的消息超过物理内存的40%,建议从从服务器拉取
当消息消费者向服务器拉取消息之后有一下情况
- 如果从服务器的slaveReadEnable设置为false,则下次拉取,从主服务器拉取
- 如果从服务器允许读取并且从服务器积压的消息没有超过其物理内存的40%,下次拉取使用的Broker为订阅组的broker指定的Broker服务器,该值默认为0,代表主服务器
- 如果从服务器允许读取并且从服务器积压的消息超过40%,下次拉取使用Broker为订阅组的
转载地址:http://ynkgn.baihongyu.com/
你可能感兴趣的文章
poj 2481 Cows(树状数组)题目有陷阱,转换后与stars类似
查看>>
poj 3067 Japan(树状数组,注意题目向树状数组的转换)
查看>>
A. On Segment's Own Points
查看>>
codeforces 397B. On Corruption and Numbers
查看>>
问题 E : 坤哥的难题 (题目本来觉得很难,但是数据很水,居然简单的for就AC)
查看>>
问题 F : 8 (做了这道题目,我才发现原来汉语的题目是如此的难懂)
查看>>
SqlMapConfig.xml中的setting属性设置
查看>>
hdu 3172 Virtual Friends(简单并查集)
查看>>
find the most comfortable road(并查集加贪心)
查看>>
Junk-Mail Filter(并查集,删除结点,虚父节点)
查看>>
A Bug's Life (并查集,同性恋问题,注意处理性别)
查看>>
True Liars (并查集+dp,待续、、)
查看>>
选美大赛(线段树)
查看>>
超级玛丽(简单模拟超时)
查看>>
括号东东(dp+字符串)
查看>>
hdu 1558 Segment set(并查集+计算几何线段相交)
查看>>
hdu 2818 Building Block(并查集,输出一元素下边有多少)
查看>>
Minimum Inversion Number(线段树求逆序数)
查看>>
hdu 1166 敌兵布阵(线段树,只更新叶子节点)
查看>>
Billboard (线段树更新叶子节点)
查看>>